[객체지향의 시작]
객체? -> 플레이어, 몬스터, GameRoom 등 오브젝트들
team by team 이지만 멤버변수를 명시적으로 표현할 때 접두어 m_, _, m 을 붙이는 방법들이 있다.
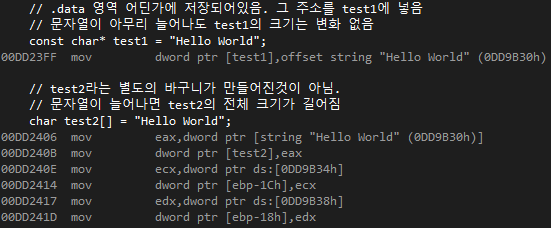
class는 일종의 설계도이다.
[생성자와 소멸자]
생성자는 오버로딩이 가능하지만 소멸자는 한개만 존재할 수 있다. 반환 타입이 없다.
기본 생성자 (인자 없음)
복사 생성자 (자기 자신의 클래스 참조 타입을 인자로 받음). 일반적으로 똑같은 데이터를 지닌 객체가 생성되길 기대함
기타 생성자. 인자를 1개만 받는 기타 생성자를 타입 변환 생성자 라고 부르기도 함
암시적 생성자(Implicit)
생성자를 명시적(Explicit)으로 만들지 않으면 기본 생성자가 컴파일러에 의해 자동으로 만들어짐.
생성자를 하나라도 명시적으로 정의해뒀다면 기본 생성자는 더 이상 자동으로 만들어주지 않는다.
[상속성]
Inheritance
상속받은 객체의 생성자와 소멸자는 부모 생성자 - 자식 생성자 - 자식 소멸자 - 부모 소멸자 순으로 작동하기는 하는데 디스어셈블리로 열어보면 우선 자식 생성자에 접근하기 바로 직전에 부모 생성자에 접근하는걸 확인할 수 있다.
[은닉성]
은닉성(Data Hiding) ≒ 캡슐화(Encapsulation)
캡슐화 : 연관된 데이터와 함수를 논리적으로 묶어놓은 것
몰라도 되는 데이터는 깔끔하게 숨기겠다.
데이터를 숨기는 이유는 1) 정말 위험하고 건드리면 안돼서, 2) 다른 경로로 접근하길 원해서 이다.
멤버 접근 지정자 : public, protected, private
대형 프로젝트의 경우 내가 설계한 모든 클래스들을 다른 사람들도 다 이해할 거라고 착각하면 안된다.
오히려 다른 사람들은 다 모른다고 가정해야 한다.
외부에서 호출하면 안되는 함수들을 public으로 만들다보면 로직이 꼬일 수 있으니 같이 동작해야 하는 로직은 하나로 묶어서 사용하는 것이 좋다.
상속 접근 지정자 : 부모 클래스의 접근 지정자의 최대치를 지정한다고 보면 된다. private 상속 시 자식 클래스들은 조부모 클래스에 아무것도 접근하지 못한다.
private, protected 상속은 웬만해서 써 볼 일이 없을 것이다.
[다형성]
Polymorphism : 겉은 똑같지만 기능이 다르게 동작함
오버로딩 : 함수 중복 정의 = 함수 이름의 재사용
오버라이딩 : 함수 재정의 = 부모 클래스의 함수를 자식 클래스에서 재정의
정적 바인딩 : 컴파일 시점에 결정. 일반 함수들은 정적 바인딩을 사용
동적 바인딩 : 실행 시점에 결정 (<- 면접 단골 질문)
동적 바인딩을 원한다면 가상 함수(Virtual function)을 사용해야 한다.
가상 함수는 재정의를 하더라도 가상 함수이다. 자식 클래스에서 virtual 키워드를 떼더라도 여전히 가상 함수이다.
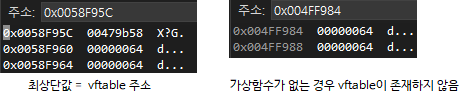
객체가 어떤 타입인지를 알아서 호출해줄까? -> 가상 함수 테이블 (vftable, v-table)
가상 함수가 하나라도 포함된 객체의 경우 메모리에 가상 함수 테이블이 생성되는 것을 확인할 수 있다.
vftable을 채우는건 생성자의 선처리 과정에서 이루어지게 된다.
순수 가상 함수 : 구현은 없고 인터페이스만 전달하는 용도로 사용하고 싶은 경우
순수 가상 함수가 하나라도 존재하는 클래스는 추상 클래스로 인식하게 되어서 직접적으로 객체를 만들 수 없게된다.
[초기화 리스트]
멤버 변수를 초기화 하는 방법은 몇 가지가 있다.
생성자 내에서, 초기화 리스트, 클래스 내에서 선언과 동시에 초기화(C++11)
초기화 리스트는
상속 관계(is-a)에서 원하는 부모 생성자를 호출하거나,
포함 관계(has-a) 관계의 객체 생성자를 호출할 때,
정의와 동시에 초기화가 필요한 경우(참조 타입, const 타입)에 필요하다,
Is-A : 상속 관계
Has-A : 포함 관계. 선처리 과정에서 생성자가 호출되기 때문에 객체를 소유한 생성자에서 초기화를 하면 생성자가 두번 호출되는 일이 발생한다.
예를 들어 A객체가 B객체를 소유하고 A생성자 내에서 B객체의 생성자를 호출 시 [A생성자-B생성자-B소멸자-B생성자] 라는 흐름이 발생한다.
[연산자 오버로딩]
연산자 함수를 정의해야 한다.
멤버 연산자 함수: 클래스 내에서 정의된다. 연산은 A op B 형태에서 left to right로 연산한다. A는 기준 피연산자 라고 한다.
A가 클래스가 아니면 사용이 불가능 하다.
class Position
{
public:
Position operator+(const Position& arg)
{
// do something
}
}
전역 연산자 함수: A op B 형태라면 A, B 모두 연산자 함수의 피연산자로 만들어줄 수 있다.
Position operator+(const int a, const Position& b)
{
// do something
}
상황에 따라 맞는걸 골라서 사용하게 된다.
대입 연산자 같은 경우는 전역 연산자 함수로 만들 수 없다.
참고) 객체의 선언과 동시에 초기화 하는것과 대입 연산자는 다르다.
복사 대입 연산자: 대입 연산자 중, 자기 자신을 참조 타입으로 받는 것. 동적할당에서 다룰 예정
모든 연산자를 다 오버로딩 할 수 있는 것은 아니다. (:: . * 이런건 안됨)
++, -- 같은 단항 연산자의 경우 전위형은 operator++(), 후위형은 operator++(int) 와 같은 형태로 구분할 수 있다.
다만 전위형은 this 레퍼런스를 반환해 주어야 한다.
..
// 복사 대입 연산자. ref타입을 인자로 받음
Position& operator=(const Position& arg);
// 후위형. 복사된 값 반환
Position operator+(int);
..
Position pos1;
Position pos2;
pos2 = pos1++; //ref 요구 = 복사값 반환 -> 타입 불일치
타입이 일치하지 않지만 문법상 정상 실행이 되는 이유는 const가 붙었기 때문이다.
디스어셈블리로 추적해보면 operator++로 값이 반환되고 해당 값이 스택 영역에 임시로 저장된 후 해당 영역을 레퍼런스로 operator=에 넘겨주는 형태가 된다.
Position pos1;
Position pos2;
Position temp = pos1++;
pos2 = temp;
즉, 이런 형태로 작동하는 셈이다.
[객체지향 마무리]
class와 struct의 미묘한 차이
struct의 기본 접근 지정자는 public, class는 private이다.
static 변수
개별 객체가 아닌 클래스 자체와 연관이 생긴다.
객체와는 다른 공간에 할당된다.
전역변수와 마찬가지로 .data(.bss) 영역에 할당된다.
static 함수
개별 객체가 아닌 클래스 자체와 연관이 생긴다.
static 함수의 경우 static 변수를 조작하는것은 문제 없지만 일반 멤버 변수는 조작할 수 없다.