공간 분할 (Spatial Partition)
객체를 효과적으로 찾기 위해 객체 위치에 따라 구성되는 자료구조에 저장한다.
동기
게임 월드에는 공간이라는 개념이 있기 때문에 게임 오브젝트는 공간 어딘가의 위치에 존재하게 된다.
플레이어는 공간 내에 존재하는 모든 오브젝트와 거리에 상관없이 상호작용 하거나 렌더링 할 필요 없이 일정 거리 이내의 오브젝트들과 상호작용 하거나 렌더링 해주는걸로 충분하다.
이를 위해서는 주변에 어떤 객체들이 있는지를 알아야 한다.
void handleMelee(Unit* units[], int numUnits) {
for (int a = 0; a < numUnits - 1; ++a) {
for (int b = a + 1; b < numUnits; ++b) {
if (units[a]->position() == units[b]->position()) {
handleAttack(units[a], units[b]);
}
}
}
}맵에 존재하는 유닛끼리 거리를 확인하여 공격하는 코드를 나이브하게 작성한 완전탐색 코드이다.
매 프레임마다 O(n²)의 시간 복잡도를 소모하게된다. 유닛 수가 많아지면 검사 횟수가 기하급수적으로 늘어나게 되어 성능이 수직 하락하는 문제가 생긴다.
일단 당장 눈에 보이는 문제는 정렬이 되어 있지 않다는 것이다. 만약 거리순으로 정렬이 되어있다면 이진 탐색 등으로 매우 빠른 시간내에 주변 유닛을 탐색할 수 있다.
위의 예시처럼 전체 범위에 대해 1차원 배열을 사용한 것처럼 여러 범위로 쪼개어 확장시키면 2차원 이상의 공간을 사용할 수 있고 이것이 바로 공간 분할 패턴이다.
패턴
객체들은 공간 위에서의 위치 값을 갖는다. 이들 객체를 객체 위치에 따라 구성되는 공간 자료구조에 저장한다. 공간 자료구조를 통해서 같은 위치 혹은 주변에 있는 객체를 빠르게 찾을 수 있다. 객체 위치가 바뀌면 공간 자료구조도 업데이트해 계속해서 객체를 찾을 수 있도록 한다.
언제 쓸 것인가?
동적 오브젝트 뿐만 아니라 지형 등의 정적 오브젝트를 저장하는 데에도 흔하게 사용된다.
복잡한 게임에서는 콘텐츠별로 공간 분할 자료구조를 따로 두기도 한다.
위치 값이 있는 객체가 많고, 위치에 따라 객체를 찾는 질의가 성능에 영향을 줄 정도로 잦을 때 사용한다.
주의사항
공간 분할 패턴을 사용하면 O(n²)인 복잡도를 쓸만한 수준으로 낮출 수 있지만 이는 객체가 많을수록 의미가 생긴다.
만약 n이 충분히 작으면 굳이 신경 쓸 필요가 없다.
객체를 위치에 따라 정리하기 때문에 객체의 위치 변경을 처리하기가 매우 어렵다.
객체의 바뀐 위치에 맞춰서 자료구조를 재정리해야 하기 때문에 코드가 더 복잡해질 뿐더러 CPU도 더 많이 소모하므로 공간 분할 패턴을 적용할만한 값어치가 있는지를 먼저 확인해보아야 한다.
게다가 일반적인 최적화들처럼 속도를 위해 메모리를 희생하기 때문에 메모리가 부족한 환경이라면 오히려 손해일 수도 있다.
예제

전체 전장을 모눈종이의 칸처럼 고정 크기로 나누고 유닛들을 배열이 아니라 격자 안에 넣는다.
칸마다 유닛 리스트가 존재하고 유닛이 해당 칸의 범위 안에 들어오면 그 유닛을 리스트에 저장한다.
그 이후에 전투를 처리할 때는 같은 칸 안에 들어있는 유닛만 신경 쓰면 되기 때문에 훨씬 적은 숫자의 유닛들과 비교할 수 있게 된다.
class Unit {
friend class Grid;
public:
Unit(Grid* grid, double x, double y) : grid_(grid), x_(x), y_(y) {}
void move(double x, double y);
private:
double x_, y_;
Grid* grid_;
Unit* prev_;
Unit* next_;
};
class Grid {
public:
Grid() {
for (int x = 0; x < NUM_CELLS; ++x) {
for (int y = 0; y < NUM_CELLS; ++y) {
cells_[x][y] = nullptr;
}
}
}
static const int NUM_CELLS = 10;
static const int CELL_SIZE = 20;
private:
Unit* cells_[NUM_CELLS][NUM_CELLS];
};각 유닛은 2차원 위치 좌표와 자신이 속해있는 그리드의 포인터를 가진다.
연결 리스트로 구현할 것이기 때문에 prev, next 포인터 역시 만들어둔다.

Unit::Unit(Grid* grid, double x, double y)
: grid_(grid), x_(x), y_(y), prev_(nullptr), next_(nullptr) {
grid_->add(this);
}
void Grid::add(Unit* unit) {
int cellX = (int)(unit->x_ / Grid::CELL_SIZE);
int cellY = (int)(unit->y_ / Grid::CELL_SIZE);
unit->prev_ = nullptr;
unit->next_ = cells+[cellX][cellY];
cells_[cellX][cellY] = unit;
if (unit->next_ != nullptr)
unit->next_->prev_ = unit;
}이제 유닛은 새로 생성될때마다 그리드에 속함과 동시에 리스트에 추가한다. 흐름 자체는 단순하다.
void Grid::handleMelee() {
for (int x = ; x < NUM_CELLS; ++x) {
for (int y = 0; y < NUM_CELLS; ++y) {
handleCell(cells_[x][y]);
}
}
}
void Grid::handleCell(Unit* unit) {
while (unit != nullptr) {
Unit* other = unit->next_;
while (other != nullptr) {
if (unit->x_ == other->x_ && unit->y_ == other->y_)
handleAttack(unit, other);
other = other->next_;
}
unit = unit->next_;
}
}코드만 보면 기존과 동일하게 모든 칸을 순회하며 함수를 호출하지만 차이가 있다면 맵에 존재하는 모든 유닛을 완전탐색 하는것이 아니라 같은 칸에 들어있는 유닛들만 확인하게 되므로 해당 칸을 기준으로 본다면 연산량이 대폭 줄어든다.
성능적인 문제는 해결된듯 하지만 유닛이 항상 칸에 묶여 있어야 하다보니 유닛이 다른 칸으로 이동할 때마다 현재 칸의 리스트에서 제거하고 이동하는 칸의 리스트에 추가해주는 작업을 해주어야 한다.
void Unit::move(double x, double y) {
grid_->move(this, x, y);
}
void Grid::move(Unit* unit, double x, double y) {
// 기존에 위치하던 칸 확인
int oldCellX = (int)(unit->x_ / Grid::CELL_SIZE);
int oldCellY = (int)(unit->y_ / Grid::CELL_SIZE);
// 새로 이동할 칸 확인
int cellX = (int)(x / Grid::CELL_SIZE);
int cellY = (int)(y / Grid::CELL_SIZE);
unit->x_ = x;
unit->y_ = y;
// 변동이 없으면 작업X
if (oldCellX == cellX && oldCellY == cellY)
return;
if (unit->prev_ != nullptr)
unit->prev_->next_ = unit->next_;
if (unit->next_ != nullptr)
unit->next_->prev_ = unit->prev_;
// 헤드 교체
if (cells_[oldCellX][oldCellY] == unit)
cells_[oldCellX][oldCellY] = unit->next_;
add(unit);
}많은 유닛들을 매 프레임마다 연결 리스트에서 넣었다 뺄 수 있기 때문에 추가와 삭제가 빠른 이중 연결 리스트를 이용할 수밖에 없다.
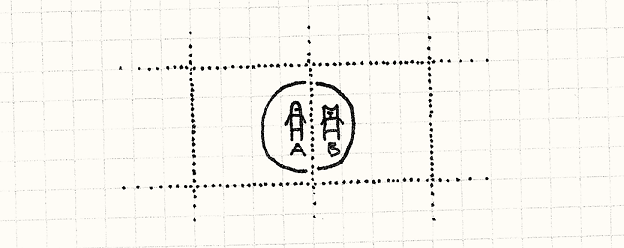
여태까지는 같은 칸 안에 있는 유닛들만 검사했지만, 장거리 공격이 가능한 경우라면 같은 칸이 아니더라도 범위를 조금 더 넓게 검사하도록 바꾸면 된다.
위의 그림처럼 사거리 안에 들었음에도 다른 칸인 경우를 꼭 고려해야 한다.
void Grid::handleUnit(Unit* unit, Unit* other) {
while (other != nullptr) {
if (distance(unit, other) < ATTACK_DISTANCE)
handleAttack(unit, other);
other = other->next_;
}
}
void Grid::handleCell(int x, int y) {
Unit* unit = cells_[x][y];
while (unit != nullptr) {
handleUnit(unit, unit->next_);
unit = unit->next_;
}
}handleCell 안에서 내부 루프를 따로 빼내어 HandleUnit으로 만든다.
handleCell은 더 이상 유닛 리스트가 아닌 칸의 좌표 값을 받도록 변경한다.
void Grid::handleCell(int x, int y) {
Unit* unit = cells_[x][y];
while (unit != nullptr) {
handleUnit(unit, unit->next_);
if (x > 0) handleUnit(unit, cells_[x-1][y]);
if (y > 0) handleUnit(unit, cells_[x][y-1]);
if (x > 0 && y > 0) handleUnit(unit, cells_[x-1][y-1]);
if (x > 0 && y < NUM_CELLS-1) handleUnit(unit, cells_[x-1][y-1]);
unit = unit->next_;
}
}handleCell을 확장시켜서 주변 8칸 중 좌측 4칸에 대해 충돌 여부를 검사한다.
절반만 검사하는 이유는 중복 처리 문제를 해결하기 위함이지만 일반적으로는 A, B의 관계가 비대칭이기 때문에 주변 칸을 모두 검사해야한다.
디자인 결정
◾ 공간을 계층적으로 나눌 것인가, 균등하게 나눌 것인가?
◾ 균등하게 나눈다면 : 더 단순하고 메모리 사용량이 일정하다. 또한 구조가 일정하기 때문에 객체의 위치 변경 시 자료구조의 업데이트 속도가 빠르다.
◾ 계층적으로 나눈다면 : 빈 공간을 훨씬 효율적으로 처리할 수 있고 밀집된 영역도 효과적으로 처리할 수 있다.
◾ 객체 개수에 따라 분할 횟수가 달라지는가?
유닛 개수와 위치에 따라 분할 크기를 조절한다. 예제처럼 크기를 모두 균일하게 분할했다가 모든 유닛이 한 칸에 몰려있다면 O(n²)으로 성능이 퇴보하기 때문이다.
◾ 객체 개수와 상관없이 분할한다면 : 유닛 리스트의 추가/삭제는 빠르게 이루어지지만 특정 영역에 유닛이 몰리면 성능 하락의 문제가 발생한다.
◾ 객체 개수에 따라 영역이 다르게 분할된다면 : 공간을 반으로 분할했을 때, 양쪽에 균일한 객체가 들어있도록 재귀적으로 쪼갠다. 영역의 균형 잡힘을 보장할 수 있는데, 이는 성능이 좋아지게 한다기 보다는 성능을 일정하게 유지시킬 수 있다. 그리고 전체 객체에 대해서 한 번에 분할해두는게 훨씬 효과적이다. 보통 이런 분할 기법은 정적 지형이나 아트 리소스에 자주 사용된다.
◾ 영역 분할은 고정되어 있지만, 계층은 객체 개수에 따라 달라진다면 : 쿼드트리를 생각하면 된다. 위 두가지 방법의 장점을 모두 취할 수 있다.
◾ 객체를 공간 분할 자료구조에만 저장하는가?
◾ 객체를 공간 분할 자료구조에만 저장한다면 : 컬렉션이 두 개가 되면서 생기는 메모리 비용과 복잡도를 피할 수 있다.
◾ 다른 컬렉션에도 객체를 둔다면 : 전체 객체를 더 빠르게 순회할 수 있다.
공간 분할 자료구조와 관련된 내용으로는 격자, 쿼드트리, 이진 공간 분할, k-d트리, 경계 볼륨 계층구조를 찾아보면 된다.
덧붙여서,
격자의 1차원 버전은 버킷 정렬
BSP, k-d트리, BVH의 1차원 버전은 이진 탐색 트리
쿼드트리, 옥트리의 1차원 버전은 트라이다.
'도서 > 게임 프로그래밍 패턴' 카테고리의 다른 글
| 최적화 패턴 : 객체 풀 (0) | 2023.03.03 |
|---|---|
| 최적화 패턴 : 더티 플래그 (0) | 2023.03.03 |
| 최적화 패턴 : 데이터 지역성 (0) | 2023.03.03 |
| 디커플링 패턴 : 서비스 중개자 (0) | 2023.02.28 |
| 디커플링 패턴 : 이벤트 큐 (0) | 2023.02.28 |