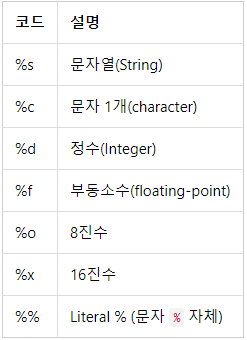
튜플과 리스트는 사용법이 완전히 동일하지만 튜플의 요소는 삭제나 변경이 불가능하다.
그렇기에 튜플은 삭제나 변경과 관련된 메소드가 없다.
인덱스의 -1은 리스트의 가장 끝을 의미한다.
문자열과 마찬가지로 슬라이싱, +, * 연산이 가능하며 기능이 동일하다.
리스트 요소의 삭제는 remove와 pop함수, 그리고 del을 사용한다.
pop의 인자가 없을시 가장 마지막 요소가 반환되고 삭제됨
a = [1,2,2,4]
a.remove(2) # 가장 먼저 발견되는 값 삭제. 1,2,4
a.pop(2) # 해당 인덱스 값 반환 후 삭제. 1,2
a = [1,2,2,4]
del a[0] # 2,2,4
del a[1:] # 2
리스트의 값을 복사하고자 할 때
a = [1,2,3] # id(a) 4303029896
b = a # id(b) 4303029896단순히 리스트를 대입시키게 되면 [1, 2, 3] 리스트를 참조하는 변수가 1개에서 2개로 늘어난 것과 마찬가지가 된다.
즉, 얕은 복사가 일어나게 된다.
a = [1, 2, 3]
b = a.copy() # 메소드를 이용하거나
b = a[:] # 전체범위에 해당하는 새로운 리스트를 넘겨준다
리스트 관련 함수들
append : 맨 뒤에 요소를 추가시킨다
sort : 기본적으로 오름차순 정렬
reverse : 순서를 뒤집는다
index : 문자열의 index와 같다. 하지만 find는 없다
insert : 리스트에 요소 삽입
a = [1, 2, 3]
a.insert(0,4)
# [4, 1, 2, 3]count : 리스트 안에 들어있는 인자의 개수를 반환함
extend : 인자로 받은 리스트를 추가시켜 확장시킨다
'프로그래밍 > Python' 카테고리의 다른 글
| [자료형] 집합 (0) | 2022.07.22 |
|---|---|
| [자료형] 딕셔너리(사전) (0) | 2022.07.22 |
| [자료형] 문자열 (0) | 2022.07.22 |
| sort 함수에서 key가 다중조건일때 (0) | 2022.07.18 |
| 파이썬 문법 메모 (0) | 2022.07.14 |