
소수의 판별
하나의 소수 판별
정석적으로 판별하는 경우 모든 수를 탐색해야 하기 때문에 O(N)의 시간 복잡도를 가진다.
특정한 자연수의 모든 약수를 찾을 때 가운데 약수(제곱근)까지만 확인하면 되는 특징을 이용하면 O(N½)로 줄일 수 있다.
다수의 소수 판별
에라토스테네스의 체 알고리즘을 사용하면 된다.
O(NloglogN)의 시간 복잡도를 가진다. N=1,000,000일 때, 약 4,000,000이다.
하지만 메모리가 많이 필요하기 때문에 너무 큰 숫자는 사용하기 어렵다.
n = 1000
array = [True for i in range(n + 1)]
array[1] = False # 1은 소수가 아님
# 2부터 n의 제곱근까지 확인
for i in range(2, int(n**0.5)+1):
if array[i] == True:
# i의 배수를 모두 지움
for j in range(i * 2, n + 1, i):
array[j] = False
# 모든 소수 출력
for i in range(2, n + 1):
if array[i]:
print(i, end=' ')
투 포인터 : 리스트에 순차적으로 접근해야 할 때, 두 개의 점의 위치를 기록하면서 처리하는 알고리즘
특정한 합을 가지는 부분 연속 수열 찾기가 대표적인 문제이다.
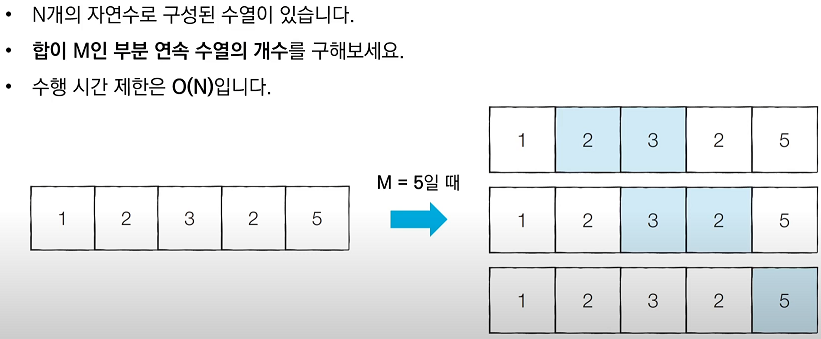
1. 시작점(start)과 끝점(end)이 첫 번째 원소의 인덱스를 가리키도록 한다.
2. 현재 부분 합이 M과 같다면, 카운트한다.
3. 현재 부분 합이 M보다 작다면, end를 1 증가시킨다.
4. 현재 부분 합이 M보다 크거나 같다면, start를 1 증가시킨다.
5. 모든 경우를 확인할 때까지 2번부터 4번까지의 과정을 반복한다.
n = 5 # 데이터의 개수 n
m = 5 # 찾고자 하는 부분합 m
data = [1, 2, 3, 2, 5]
count = 0
interval_sum = 0
end = 0
for start in range(n):
# end를 가능한 만큼 이동시키기
while interval_sum < m and end < n:
interval_sum += data[end]
end += 1
if interval_sum == m:
count += 1
interval_sum -= data[start]
print(count)
구간 합 : 특정 구간의 모든 수를 합한 값을 계산하는 것
*접두사 합 : 배열의 맨 앞부터 특정 위치까지의 합을 미리 구해 놓은 것
접두사 합이 이미 계산되어 있다면 많은 수의 쿼리가 들어왔을 때, O(1)로 모두 처리가 가능하다.

순열과 조합
파이썬3 이상에서는 순열과 조합 기능을 제공하는 라이브러리를 기본으로 제공하고 있다.
코딩 테스트에서는 경우의 수 값만 출력하는 것이 아니라 모든 경우(사건)을 다 출력하도록 요구하기도 하는데, 이 때는 itertools 라이브러리를 이용한다.
*순열 : 서로 다른 n개에서 r개를 선택하여 일렬로 나열하는 것.
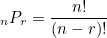
itertools의 permutations 함수를 이용하면 된다. 함수의 반환값이 리스트 형태가 아니기 때문에 리스트로 받아서 바꿔줄 필요가 있다.
*조합 : 서로 다른 n개에서 순서에 상관없이 서로 다른 r개를 선택하는 것
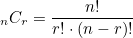
itertools의 combinations 함수를 이용하면 된다. 위와 동일하다.
[1, 2, 3] 에서 서로 다른 2개의 원소를 뽑아서 나열할 때, 순열은 가능한 모든 순서를 고려하기 때문에 [1, 2] 와 [2, 1] 등을 포함하여 경우의 수가 6개가 존재한다.
하지만 조합에서는 [1, 2] 와 [2, 1]은 동일한 것으로 보고 [1, 2]만 포함하게 되어 경우의 수는 3개만 존재하게 된다.
'알고리즘 > 공부' 카테고리의 다른 글
| 최장 공통 부분 수열 (LCS) (0) | 2023.05.20 |
|---|---|
| PS 활용 문법들 (0) | 2022.12.29 |
| 위상정렬 (0) | 2022.07.17 |
| 토막지식/짧은내용들 정리 (0) | 2022.07.16 |
| 이코테 개념 정리 (0) | 2022.07.14 |