
데이터 지역성 (Data Locality)
CPU 캐시를 최대한 활용할 수 있도록 데이터를 배치해 메모리 접근 속도를 높인다.
동기
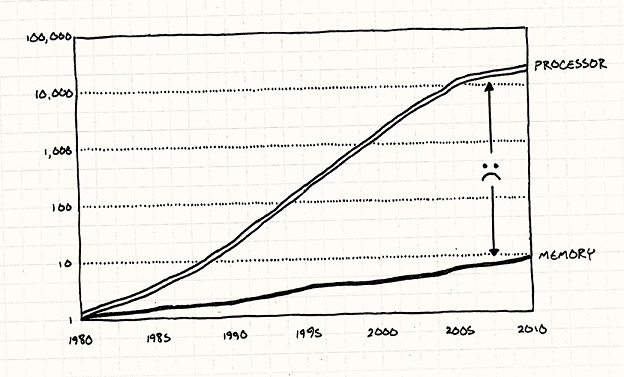
하드웨어 발전을 따라서 데이터의 연산 속도는 빨라졌지만 데이터를 가져오는 속도는 크게 달라지지 않았다.
CPU는 램에서 데이터를 1바이트 가져오는 데에만 몇 백 CPU 사이클 정도를 소모한다. 매 번 이렇게 사이클을 소모하면 사실상 거의 대부분의 시간을 데이터를 기다리는 대기시간일텐데, 실제로는 그렇게 동작하지 않는다.
그 이유는 참조 지역성에 기반을 둔다.
데이터를 1바이트라도 가져오게 된다면 인접한 연속된 메모리를 선택하여 캐시에 복사한다.
추후 필요한 데이터가 캐시 라인 안에 들어있다면 CPU는 대기하지 않고 데이터를 바로 가져온다.
필요한 데이터가 없어서 캐시 미스가 발생하면 그때는 CPU가 멈춰서 데이터를 기다리며 사이클을 낭비한다.
그래서 자료구조를 최대한 잘 만들어서 캐시 미스가 발생하는 것을 최대한 피해야 한다.
패턴
CPU는 메모리 접근 속도를 높이기 위한 캐시를 여러 개 둔다. 캐시를 사용하면 최근에 접근한 메모리 근처에 있는 메모리를 훨씬 빠르게 접근할 수 있다. 데이터 지역성을 높일수록, 즉 데이터를 처리하는 순서대로 연속된 메모리에 둘수록 캐시를 통해서 성능을 향상할 수 있다.
언제 쓸 것인가?
다른 최적화 기법과 마찬가지로, 성능 문제가 있을 때 써야 한다. 필요없는 곳에 최적화를 해봤자 코드만 복잡해지고 유연성이 떨어질 뿐이다.
특히나 데이터 지역성 패턴은 성능 문제가 캐시 미스 때문인지를 확인해봐야 한다. 다른 이유 때문에 도입하는 것이라면 전혀 도움이 안 된다.
처음부터 캐시 최적화를 하겠다고 많은 시간을 낭비할 필요는 없지만 자료구조를 캐시하기 좋게 만들려고 노력할 필요는 있다.
주의사항
C++에서는 인터페이스를 사용하려면 포인터나 레퍼런스를 통해 객체에 접근해야 한다. 그런데 포인터를 쓰게 되면 캐시 미스가 발생하게 된다.
그래서 데이터 지역성 패턴을 적용하려면 추상화를 일부 희생해야한다.
예제
..
private:
AIComponent* ai_;
PhysicsComponent* physics_;
RenderComponent* render_;
/* --- */
while (!gameOver) {
for (int i = 0; i < numEntities; ++i)
entities[i]->ai()->update();
for (int i = 0; i < numEntities; ++i)
entities[i]->physics()->update();
for (int i = 0; i < numEntities; ++i)
entities[i]->render()->update();
}컴포넌트 패턴을 통해 나누어진 게임 개체들을 게임 루프 안에서 호출한다면 위와 같은 코드가 될 것이다.
월드에 있는 모든 개체를 거대한 포인터 배열 하나로 관리하는 것이다.
동작 자체는 별 문제가 없어보이지만 캐시 적중의 측면에서 접근하면 난장판 이라는 것을 알 수 있다.
게임 개체가 배열에 포인터로 저장되어 있기 때문에 배열 값에 접근할 때마다 포인터를 따라가며 캐시 미스가 계속 발생하게 된다.
..
AIComponent* aiComponents = new AIComponent[MAX_ENTITIES];
PhysicsComponent* physicsComponents = new PhysicsComponent[MAX_ENTITIES];
RenderComponent* renderComponents = new RenderComponent[MAX_ENTITIES];
/* --- */
while (!gameOver) {
for (int i = 0; i < numEntities; ++i)
aiComponents[i].update();
for (int i = 0; i < numEntities; ++i)
physicsComponents[i].update();
for (int i = 0; i < numEntities; ++i)
renderComponents[i].update();
}각 개체 안에 포인터로 들고있는 대신 외부의 동적 배열로 끌어내려서 포인터가 아닌 객체에 바로 접근하여 캐시 적중률을 높인다.
작업 전과 후의 속도 차이는 실행 환경마다 다르겠지만 책 기준으로는 50배가 차이 난다.
캡슐화도 많이 깨먹지 않아서 나쁘지 않다. 게임 루프에서 컴포넌트를 직접 업데이트 하기는 하지만 이전 코드도 어차피 함수 호출로 컴포넌트에 직접 접근하고 있었다. 단순히 컴포넌트가 사용되는 방식만 바뀌었을 뿐이다.
본래 게임 개체(GameEntity) 안에 있던 컴포넌트를 게임 루프로 끌어내렸기 때문에 게임 개체 클래스는 딱히 들고 있을만한 컴포넌트는 없지만 그렇다고 게임 개체 클래스를 없앨 필요는 없다.
대신 자기가 본래 소유했어야 할 컴포넌트에 대한 포인터를 가지도록 만들면 된다.
이번에는 파티클 시스템을 예로 들어보자.
class Particle {
public:
void update() { /* ... */ }
};
class ParticleSystem {
public:
ParticleSystem() : numParticles_(0) {}
void update() {
for (int i = 0; i < numParticles_; ++i)
particles_[i].update();
}
private:
static const int MAX_PARTICLES = 100000;
int numParticles_;
Particle particles_[MAX_PARTICLES];
};파티클을 객체 풀에 관리하는 파티클 시스템 클래스이다.
항상 객체 풀에 들어있는 모든 파티클을 사용하는 것은 아니기 때문에 루프를 전부 순회하며 처리할 필요는 없다.
대신 플래그 변수를 둬서 활성화된 파티클만 골라서 처리시키면 간단하게 해결 될 것이다.
하지만 이것 역시 캐시 적중에 관한 측면에서 보면 같이 읽어들인 인접한 파티클 데이터들이 활성화된 상태가 아니라면 무용지물이 된다.
게다가 활성화된 파티클이 적을수록 메모리를 더 자주 건너뛰게 되어서 이 방법 역시 캐시 미스가 더 자주 발생한다.
이번에는 활성화된 파티클들만 앞으로 모아서 처리하면 캐시 적중률이 높아진다.
정렬이라는 단어를 사용할 수 있겠지만 사실 매 프레임마다 배열의 모든 요소들을 정렬할 필요는 없고 활성 파티클만 앞으로 모아두면 된다.
// 비활성 -> 활성
void ParticleSystem::activeParticle(int index) {
assert(index >= numActive_);
swap(particles_[numActive_], particles_[index]);
numActive_++;
}
// 활성 -> 비활성
void ParticleSystem::deactiveParticle(int index) {
assert(index < numActive_);
numActive_--;
swap(particles_[numActive_], particles_[index]);
}성능적으로는 만족스러울지 모르지만 객체지향성을 어느 정도 포기해야 한다.
덧붙여서 Particle과 ParticleSystem 클래스가 서로 강하게 커플링 되어있지만 어차피 하나의 개념이 두개의 클래스로 나누어진 것 뿐이기 때문에 크게 상관이 없다.
마지막으로 호출 횟수에 따라 구분해보자.
예를 들어 AI 컴포넌트는 현재 재생중인 애니메이션, 이동 중인 목표 지점, 스탯 등이 들어있고 매 프레임마다 값을 확인하고 변경한다.
그런데 죽을 때 어떤 아이템을 떨어트릴지에 대한 데이터는 죽는 순간 딱 한번만 사용되기 때문에 굳이 위와 같은 컴포넌트에서 멤버로 같이 관리하여 컴포넌트 크기를 늘릴 필요는 없다.
class AIComponent {
public:
// methods
private:
Animation* animation_;
double energy_;
Vector goalPos_;
LootDrop* loot_; // 사용 빈도가 적은 데이터들
};
class LootDrop {
private:
friend class AIComponent;
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};이런 데이터들을 따로 분리시켜서 포인터로 들고있게 하면 컴포넌트의 크기를 줄일 수 있기 때문에 캐시 라인에 컴포넌트를 더 올려서 캐시 적중률을 높일 수 있다.
디자인 결정
결론만 먼저 내리자면 이 패턴은 데이터를 메모리에 어떻게 배치하느냐에 따라 성능이 크게 영향을 받는다는 사고 방식을 갖게 하는 것이 목적이다. 구현 방법에 왕도는 없고 다양하게 구현할 수 있다.
그런데 데이터 지역성을 적용한다면 다형성은 어떻게 처리할 것인가에 생각해 볼 필요가 있다.
가장 쉬운 방법으로는 상속을 받지 않는것이다. 가장 안전하고 쉽고 빠르지만 상속을 받지 않기때문에 코드가 유연하지 않게 된다.
두 번째 방법으로는 타입별로 배열을 준비해서 각기 다른 배열에 넣고 관리하는 것이다. 대신 이 경우는 커플링이 생기고 확장성이 좋지 않아진다.
마지막으로 데이터 지역성을 적용하지 않고 하나의 컬렉션에 포인터를 모아놓는 방법이 있다. 캐시를 신경쓰지 않는다면 보통 이게 자연스러운 방식이다.
'도서 > 게임 프로그래밍 패턴' 카테고리의 다른 글
| 최적화 패턴 : 객체 풀 (0) | 2023.03.03 |
|---|---|
| 최적화 패턴 : 더티 플래그 (0) | 2023.03.03 |
| 디커플링 패턴 : 서비스 중개자 (0) | 2023.02.28 |
| 디커플링 패턴 : 이벤트 큐 (0) | 2023.02.28 |
| 디커플링 패턴 : 컴포넌트 (0) | 2023.02.27 |