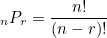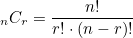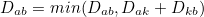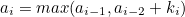n = 1000
array = [True for i in range(n + 1)]
array[1] = False # 1은 소수가 아님
# 2부터 n의 제곱근까지 확인
for i in range(2, int(n**0.5)+1):
if array[i] == True:
# i의 배수를 모두 지움
for j in range(i * 2, n + 1, i):
array[j] = False
# 모든 소수 출력
for i in range(2, n + 1):
if array[i]:
print(i, end=' ')
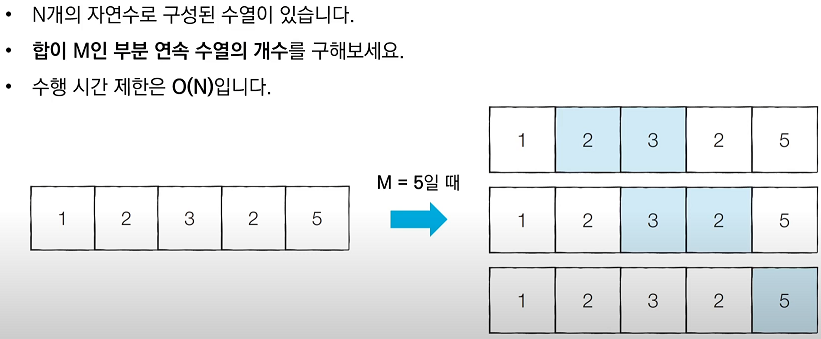
투 포인터 : 리스트에 순차적으로 접근해야 할 때, 두 개의 점의 위치를 기록하면서 처리하는 알고리즘
n = 5 # 데이터의 개수 n
m = 5 # 찾고자 하는 부분합 m
data = [1, 2, 3, 2, 5]
count = 0
interval_sum = 0
end = 0
for start in range(n):
# end를 가능한 만큼 이동시키기
while interval_sum < m and end < n:
interval_sum += data[end]
end += 1
if interval_sum == m:
count += 1
interval_sum -= data[start]
print(count)
구간 합 : 특정 구간의 모든 수를 합한 값을 계산하는 것
*접두사 합 : 배열의 맨 앞부터 특정 위치까지의 합을 미리 구해 놓은 것
접두사 합이 이미 계산되어 있다면 많은 수의 쿼리가 들어왔을 때, O(1)로 모두 처리가 가능하다.
순열과 조합
파이썬3 이상에서는 순열과 조합 기능을 제공하는 라이브러리를 기본으로 제공하고 있다.
코딩 테스트에서는 경우의 수 값만 출력하는 것이 아니라 모든 경우(사건)을 다 출력하도록 요구하기도 하는데, 이 때는 itertools 라이브러리를 이용한다.
*순열 : 서로 다른 n개에서 r개를 선택하여 일렬로 나열하는 것.
itertools의 permutations 함수를 이용하면 된다. 함수의 반환값이 리스트 형태가 아니기 때문에 리스트로 받아서 바꿔줄 필요가 있다.
*조합 : 서로 다른 n개에서 순서에 상관없이 서로 다른 r개를 선택하는 것
itertools의 combinations 함수를 이용하면 된다. 위와 동일하다.
[1, 2, 3] 에서 서로 다른 2개의 원소를 뽑아서 나열할 때, 순열은 가능한 모든 순서를 고려하기 때문에 [1, 2] 와 [2, 1] 등을 포함하여 경우의 수가 6개가 존재한다.
하지만 조합에서는 [1, 2] 와 [2, 1]은 동일한 것으로 보고 [1, 2]만 포함하게 되어 경우의 수는 3개만 존재하게 된다.
def dfs(graph, v, visited):
# 현재 노드를 방문 처리
visited[v] = True
print(v, end=' ')
# 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
# 2차원 리스트로 각 노드가 연결된 정보를 표현
graph = [
[],
[2, 3, 8],
[1, 7],
[ 1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8]
[1, 7]
]
# 1차원 리스트로 각 노드가 방문된 정보를 표현
visited = [False] * 9
dfs(graph, 1, visited)
from collections import deque
def bfs(graph, start, visited):
# 큐 구현을 위해 deque 라이브러리 사용
queue = deque([start])
# 현재 노드를 방문 처리
visited[start] = True
# 큐가 빌 때까지 반복
while queue:
v = queue.popleft()
print(v, end=' ')
# 아직 방문하지 않은 인접한 원소들을 큐에 삽입
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
# 2차원 리스트로 각 노드가 연결된 정보를 표현
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 1차원 리스트로 각 노드가 방문된 정보를 표현
visited = [False] * 9
bfs(graph, 1, visited)
DFS/BFS 구현시 첫 인덱스를 사용하지 않고 다음 인덱스부터 사용한다면 노드의 인덱스가 배열의 인덱스에 그대로 대응되기 때문에 첫 인덱스는 구현의 편의성을 위해 비워놓고 사용하는 편이다
[정렬]
데이터를 특정한 기준에 따라서 순서대로 나열하는 것
*선택정렬 :처리되지 않은 데이터 중, 가장 작은 숫자를 선택해 맨 앞의 데이터와 바꾸는것을 반복. O(N²)
*삽입정렬 :처리되지 않은 데이터를 하나씩 골라 적절한 위치에 삽입. 데이터가 거의 정렬되어 있는 상태라면 매우 빠름. O(N²)이지만 모두 정렬이 되어있는 최선의 경우에는 O(N)
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array, start, end):
# 시작 인덱스가 끝 인덱스보다 크거나 같으면 즉시 종료
if start >= end:
return
pivot = start
left = start+1
right = end
# 좌측 인덱스가 우측 인덱스보다 작을 때
while(left <= right):
# pivot보다 크거나 같은 값을 찾을 때까지 우측으로 한칸씩 이동
while(left <= end and array[left] <= array[pivot]):
left += 1
# pivot보다 작거나 같은 값을 찾을 때까지 좌측으로 한칸씩 이동
while(right > start and array[right] >= array[pivot]):
right -= 1
# 인덱스가 서로 교차하면 피벗과 right를 바꿔준다
if(left > right):
array[right], array[pivot] = array[pivot], array[right]
# 그렇지 않다면 left와 right를 바꿔준다
else:
array[left], array[right] = array[right], array[left]
# 가장 좌측부터 새로운 기준 값 직전까지의 범위로 설정
quick_sort(array, start, right-1)
# 새로운 기준 값 직후부터 가장 우측까지의 범위로 설정
quick_sort(array, right+1, end)
quick_sort(array, 0, len(array)-1)
print(array)
분할-정복의 대표적인 알고리즘.
병합 정렬과 더불어 대부분의 프로그래밍 언어들의 정렬 라이브러리의 근간이 되는 알고리즘.
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array):
# 리스트가 하나 이하의 원소만을 담고 있다면 종료
if len(array) <= 1:
return array
pivot = array[0] # 피벗은 첫 번째 원소
tail = array[1:] # 피벗을 제외한 리스트
left_side = [x for x in tail if x <= pivot] # 분할된 왼쪽 부분
right_side = [x for x in tail if x > pivot] # 분할된 오른쪽 부분
return quick_sort(left_side) + [pivot] + quick_sort(right_side)
print(quick_sort(array))
파이썬의 장점을 활용해 코드 간결화가 가능하다. 리스트 슬라이싱과 리스트 컴프리헨션 사용
단, 좌우로 분할시키는 과정에서 시간적 손해가 조금 더 있다
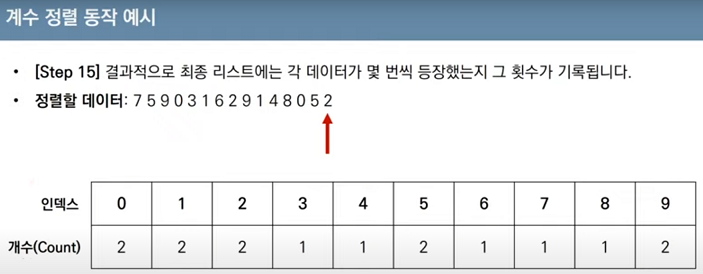
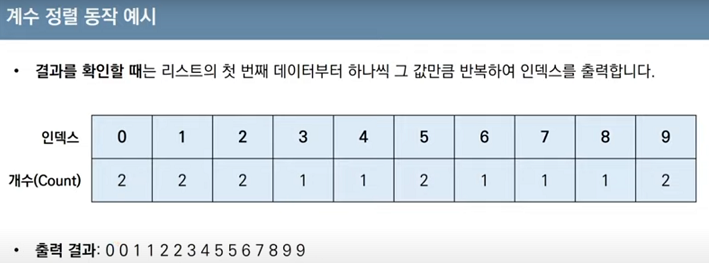
*계수정렬 :데이터의 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때 사용 가능. 특정조건을 만족할 때만 사용할 수 있지만 매우 빠르게 동작함
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8, 0, 5, 2]
count = [0] * (max(array) + 1)
for i in range(len(array)):
count[array[i]] += 1 # 각 데이터에 해당하는 인덱스의 값 증가
for i in range(len(count)): # 리스트에 기록된 정렬 정보 확인
for j in range(count[i]):
print(i, end=' ')
데이터가 0과 999,999 단 2개만 존재하는 경우 메모리를 너무 크게 잡아먹는 비효율성이 발생할 수 있다
동일한 값을 가지는 데이터가 여러 개 등장할 때 효과적으로 사용할 수 있다
코딩 테스트에서 정렬 알고리즘이 사용되는 경우를 일반적으로 3가지 문제 유형으로 나타낼 수 있다.
1. 정렬 라이브러리로 풀 수 있는 문제 :라이브러리 사용법 숙지만 하고 있으면 어렵지 않음
2. 정렬 알고리즘의 원리에 대해서 물어보는 문제 :각 정렬의 원리를 알고 있어야 문제를 풀 수 있음
3. 더 빠른 정렬이 필요한 문제 :계수 정렬 등의 다른 알고리즘을 이용하거나 문제에서 기존에 알려진 알고리즘의 구조적인 개선을 거쳐야 문제를 풀 수 있음
[이진 탐색]
*순차 탐색 :리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법
*이진 탐색 :정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법. 탐색 범위를 절반씩 줄여가기 때문에 O(logN)을 보장한다.
# 재귀로 구현
def binary_search(array, target, start, end):
if start > end:
return None
mid = (start + end) // 2
# 찾은 경우 중간점 인덱스 반환
if array[mid] == target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array[mid] > target:
return binary_search(array, target, start, mid - 1)
# 중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
else:
return binary_search(array, target, mid + 1, end)
# 원소의 개수와 찾고자 하는 값을 입력 받기
n, target = map(int, input().split())
# 전체 원소 입력 받기
array = list(map(int, input().split()))
# 이진 탐색 수행 결과 출력
result = binary_search(array, target, 0, n - 1)
if result == None:
print("원소가 존재하지 않습니다.")
else:
print(result + 1)
# 반복문으로 구현
def binary_search(array, target, start, end):
while start <= end:
mid = (start + end) // 2
# 찾은 경우 중간점 인덱스 반환
if array[mid] == target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array[mid] > target:
end = mid - 1
# 중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
else:
start = mid + 1
return None
# 원소의 개수와 찾고자 하는 값을 입력 받기
n, target = map(int, input().split())
# 전체 원소 입력 받기
array = list(map(int, input().split()))
# 이진 탐색 수행 결과 출력
result = binary_search(array, target, 0, n - 1)
if result == None:
print("원소가 존재하지 않습니다.")
else:
print(result + 1)
추가로 bisect_left, bisect_right라는 라이브러리 함수도 기본 제공된다. c++의 lower_bound, upper_bound와 동일함
값이 특정 범위에 속하는 데이터의 개수를 구하거나 같은 숫자가 몇개가 있는지 구할때 사용할 수 있다
# 한 번 계산된 결과를 메모이제이션 하기 위한 리스트 초기화
d = [0] * 100
# 피보나치 함수를 재귀함수로 구현(Top-down)
def fibo(x):
if x == 1 or x == 2:
return 1
# 이미 계산한 적 있는 문제라면 그대로 반환
if d[x] != 0:
return d[x]
# 아직 계산하지 않은 문제라면 점화식에 따라서 피보나치 결과 반환
d[x] = fibo(x - 1) + fibo(x - 2)
return d[x]
print(fibo(99))
큰 문제를 해결하기 위해 작은 문제를 호출하기 때문에 재귀는 Top-down 방식이다 한번 계산된 결과를 저장하는것을 메모이제이션(캐싱) 이라고 한다
# 앞서 계산된 결과를 저장하기 위한 DP 테이블 초기화
d = [0] * 100
d[1] = 1
d[2] = 1
n = 99
# 피보나치 함수를 반복문으로 구현(Bottom-up)
for i in range(3, n+1):
d[i] = d[i - 1] + d[i - 2]
print(d[n])
반대로 작은 문제를 모아 큰 문제를 해결하기 때문에 반복문은 Bottom-up 방식이다 Top-down 방식과 다르게 앞서 계산된 결과를 저장하기 위한 리스트를 DP 테이블 이라고 부른다
동적 계획법과 분할-정복은 모두 최적 부분 구조를 가질 때 사용할 수 있지만 분할-정복은 중복 부분의 문제가 반복적으로 계산되지 않는다
동적 계획법 문제에 접근하는 방법
그리디, 구현, 완전 탐색 등의 아이디어로 문제를 해결할 수 있는지 검토 후 풀이 방법이 떠오르지 않으면 동적 계획법을 고려해야 한다. 우선 재귀 함수로 비효율적인 완전 탐색 프로그램을 작성한 뒤에 Bottom-up 방식에서도 그대로 사용될 수 있으면 코드를 개선하는 방법을 사용할 수 있다.
일반적인 코딩 테스트 수준에서는 기본 유형의 다이나믹 프로그래밍 문제가 출제되는 경우가 많음.
[최단 경로]
다익스트라, 플로이드 워셜 알고리즘이 코딩 테스트에서 가장 많이 등장하는 유형.
*다익스트라 최단 경로 알고리즘
음의 간선이 없을 때 정상적으로 동작한다. 실제로 GPS 소프트웨어의 기본 알고리즘으로 채택되기도 한다.
최단거리 테이블을 사용하며 현재 노드까지의 최단거리를 계속 갱신한다.
매 상황에서 방문하지 않은 가장 비용이 적은 노드를 선택해가기 때문에 그리디 알고리즘으로 볼 수 있다.
구현이 쉽지만 느리고, 구현이 까다롭지만 빠른 2가지의 구현 방법이 있다.
간단한 다익스트라 알고리즘
최초 각 노드에 대한 최단 거리를 담는 1차원 리스트를 선언한다.
이후, 단계마다 방문하지 않은 노드 중에서 최단 거리가 가장 짧은 노드를 선택하기 위해 매 단계마다 1차원 리스트의 모든 원소를 순차 탐색한다.
한 번 처리된 노드의 최단 거리는 고정되어 더이상 바뀌지 않는다.
총 O(V)번에 걸쳐서 최단 거리가 가장 짧은 노드를 매번 선형 탐색해야 하고, 현재 노드와 연결된 노드를 매번 일일이 확인하기 때문에 O(V²)의 시간 복잡도를 가진다. (V는 노드의 개수)
전체 노드의 개수가 5천개 이하라면 이런 방법으로도 가능하겠지만 1만개가 넘어가는 문제라면 해결하기 어렵다
import sys
input = sys.stdin.readline
INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수, 간선의 개수를 입력받기
n, m = map(int, input().split())
# 시작 노드 번호를 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for i in range(n + 1)]
# 방문한 적이 있는지 체크하는 목적의 리스트를 만들기
visited = [False] * (n + 1)
# 최단 거리 테이블을 모두 무한으로 초기화
distance = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph[a].append((b, c))
# 방문하지 않은 노드 중에서, 가장 최단 거리가 짧은 노드의 번호를 반환
def get_smallest_node():
min_value = INF
index = 0 # 가장 최단 거리가 짧은 노드(인덱스)
for i in range(1, n + 1):
if distance[i] < min_value and not visited[i]:
min_value = distance[i]
index = i
return index
def dijkstra(start):
# 시작 노드에 대해서 초기화
distance[start] = 0
visited[start] = True
for j in graph[start]:
distance[j[0]] = j[1]
#시작 노드를 제외한 전체 n - 1개의 노드에 대해 반복
for i in range(n - 1):
# 현재 최단 거리가 가장 짧은 노드를 꺼내서, 방문 처리
now = get_smallest_node()
visited[now] = True
# 현재 노드와 연결된 다른 노드들 확인
for j in graph[now]:
cost = distance[now] + j[1]
# 현재 노드를 거쳐서 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[j[0]]:
distance[j[0]] = cost
dijkstra(start)
for i in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if distance[i] == INF:
print("INFINITY")
# 도달할 수 있는 경우 거리를 출력
else:
print(distance[i])
개선된 다익스트라 알고리즘
O(ElogV)를 보장한다. (E는 간선의 개수, V는 노드의 개수)
힙 자료구조를 사용한다.
파이썬은 PriorityQueue와 heapq 둘다 우선순위 큐를 지원하지만 보통 heapq가 더 빠르게 동작한다.
최소 힙은 원소를 꺼내면 가장 값이 작은 원소가 추출되는 특징이 있어서 우선순위 큐와 다익스트라 알고리즘의 기반이 된다.
최단 거리 테이블은 그대로 사용하고 우선순위 큐가 추가 사용된다.
우선순위 큐를 적용한 개선된 다익스트라 알고리즘의 작동 과정
1. 시작점을 설정하여 시작점->시작점 (거리 0) 의 노드를 최단 거리 테이블 갱신과 갱신된 데이터를 우선순위 큐에 (거리, 노드 번호)의 튜플로 넣어준다.
2. 우선순위 큐에서 노드를 꺼내면 현재 노드에서 거리가 가장 짧은 노드가 나오게 된다.
3. 해당 노드와 연결된 간선의 길이를 최단 거리 테이블과 비교하여 더 짧은 경우만 갱신시키고 갱신된 값만 튜플로 생성하여 우선순위 큐에 넣어준 뒤 해당 노드의 처리를 끝낸다.
4. 2-3을 우선순위 큐가 빌때까지 반복한다.
O(ElogV)의 시간 복잡도를 가진다.
우선순위 큐를 필요로 하는 다른 문제 유형과도 흡사하다는 특징이 있다.
최소 신장 트리 문제를 풀 때에도 사용되는 Prim 알고리즘의 구현이 다익스트라 알고리즘의 구현과 흡사하다.
그렇기에 다익스트라 알고리즘을 바르게 이해할 필요가 있다.
직관적으로 전체 과정은 E(개의 원소를 우선순위 큐에 넣었다가 모두 빼내는 연산과 매우 유사하다
import heapq
import sys
input = sys.stdin.readline
INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수, 간선의 개수를 입력받기
n, m = map(int, input().split())
# 시작 노드 번호를 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for i in range(n + 1)]
# 최단 거리 테이블을 모두 무한으로 초기화
distance = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph[a].append((b, c))
def dijkstra(start):
q = []
# 시작 노드로 가기 위한 최단 경로는 0으로 설정하여, 큐에 삽입
heapq.heappush(q, (0, start))
distance[start] = 0
while q: # 큐가 비어있지 않다면
# 가장 최단 거리가 짧은 노드에 대한 정보 꺼내기
dist, now = heapq.heappop(q)
# 현재 노드가 이미 처리된 적이 있는 노드라면 무시
if distance[now] < dist:
continue
# 현재 노드와 연결된 다른 인접한 노드들을 확인
for i in graph[now]:
cost = dist + i[1]
# 현재 노드를 거쳐서, 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[i[0]]:
distance[i[0]] = cost
heapq.heappush(q, (cost, i[0]))
dijkstra(start)
for i in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if distance[i] == INF:
print("INFINITY")
# 도달할 수 있는 경우 거리를 출력
else:
print(distance[i])
간단한 다익스트라 알고리즘과 다르게 최단 거리가 가장 짧은 노드를 선택하는 과정이 우선순위 큐를 이용하는 것으로 대체된다. 또한 최단 거리 테이블과 현재 꺼낸 노드의 거리를 비교하는것 자체가 일종의 방문처리이기 때문에 별도의 방문처리를 하지 않아도 된다.
플로이드-워셜 알고리즘
모든 노드에서 다른 모든 노드까지의 최단 경로를 모두 계산.
즉, 모든 지점에서 다른 모든 지점까지의 최단 경로를 모두 구해야 하는 경우에 사용할 수 있다.
다익스트라 알고리즘과 마찬가지로 단계별로 거쳐 가는 모든 노드를 기준으로 알고리즘을 수행하지만, 매 단계마다 방문하지 않은 노드 중에 최단 거리를 갖는 노드를 찾는 과정이 필요하지 않음.
다익스트라 알고리즘이 그리디 유형에 속했다면 플로이드-워셜 알고리즘은 DP 유형에 속한다.
최단 거리 테이블이 1차원이 아닌 2차원이다.
a에서 b로 가는 최단 거리보다 a에서 k를 거쳐 b로 가는 거리가 더 짧은지 검사하는 점화식
시간 복잡도는 노드의 개수 N만큼 최단 거리 테이블을 갱신해야 하기 때문에 O(N×N²) = O(N³)이다.
구현 난이도는 매우 간단하지만 N의 크기가 조금만 늘어나도 사용하기 어렵다.
그래프와 최단 거리 테이블을 따로 관리하지 않고 최초 실행시 그래프의 데이터를 받을 때, 최단 거리 테이블에 그래프의 데이터를 그대로 담아서 처리한다.
INF = int(1e9)
# 노드의 개수 및 간선의 개수를 입력받기
n = int(input())
m = int(input())
# 2차원 리스트(그래프 표현)를 만들고, 모든 값을 무한으로 초기화
graph = [[INF] * (n + 1) for _ in range(n + 1)]
# 자기 자신에서 자기 자신으로 가는 비용은 0으로 초기화
for a in range(1, n + 1):
for b in range(1, n + 1):
if a == b:
graph[a][b] = 0
# 각 간선에 대한 정보를 입력받가, 그 값으로 초기화
for _ in range(m):
# A에서 B로 가는 비용은 C라고 설정
a, b, c = map(int, input().split())
graph[a][b] = c
# 점화식에 따라 플로이드 워셜 알고리즘을 수행
for k in range(1, n + 1):
for a in range(1, n + 1):
for b in range(1, n + 1):
graph[a][b] = min(graph[a][b], graph[a][k] + graph[k][b])
# 수행된 결과를 출력
for a in range(1, n + 1):
for b in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if graph[a][b] == INF:
print("INFINITY", end=" ")
else:
print(graph[a][b], end=" ")
print()
[그래프 이론]
*서로소 집합 :공통 원소가 없는 두 집합
{1, 2} {3, 4} 는 서로소 관계이지만 {1, 2} {2, 3} 은 2가 공통적으로 포함되어 있기 때문에 서로소 관계가 아니다.
*서로소 집합 자료구조 :서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조
# 특정 원소가 속한 집합을 찾기
def find_parent(parent, x):
# 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if parent[x] != x:
return find_parent(parent, parent[x])
return x
# 두 원소가 속한 집합을 합치기
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
# 노드의 개수와 간선(union 연산)의 개수 입력받기
v, e = map(int, input().split())
parent = [0] * (v + 1) # 부모 테이블 초기화
# 부모 테이블상에서, 부모를 자기 자신으로 초기화
for i in range(1, v + 1):
parent[i] = i
# union 연산을 각각 수행
for i in range(e):
a, b = map(int, input().split())
union_parent(parent, a, b)
# 각 원소가 속한 집합 출력
print('각 원소가 속한 집합: ', end='')
for i in range(1, v + 1):
print(find_parent(parent, i), end=' ')
print()
# 부모 테이블 내용 출력
print('부모 테이블: ', end='')
for i in range(1, v + 1):
print(parent[i], end=' ')
기본적인 서로소 집합 알고리즘. 최악의 경우 find 함수는 O(V)로 작동하기때문에 효율적이지 못하다.
하지만 경로 압축이라는 아주 간단한 과정으로 최적화를 할 수 있다.
# 특정 원소가 속한 집합을 찾기
def find_parent(parent, x):
# 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
union 함수들의 처리 완료후 부모 테이블은 위와 동일하게 나오지만, 이후 find 함수를 한번 호출하면 부모 테이블의각 노드들의 부모는 루트 노드로 갱신된다.
서로소 집합 알고리즘의 시간 복잡도는 대략적으로 O(V+MlogV)이다.
노드의 개수가 1000개이고 union과 find연산이 총 100만번 수행된다면 대략 1000만번 가량의 연산이 수행된다.
시간 복잡도를 줄일 수 있는 방법은 여러가지가 더 있지만 코딩 테스트 수준에서는 경로 압축만 적용해도 충분하다.
*서로소 집합을 활용한 사이클 판별 : 무방향 그래프 내에서의 사이클을 판별할 때 사용할 수 있다.
# 특정 원소가 속한 집합을 찾기
def find_parent(parent, x):
# 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
# 두 원소가 속한 집합을 합치기
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
# 노드의 개수와 간선(union 연산)의 개수 입력받기
v, e = map(int, input().split())
parent = [0] * (v + 1) # 부모 테이블 초기화
# 부모 테이블상에서, 부모를 자기 자신으로 초기화
for i in range(1, v + 1):
parent[i] = i
cycle = False # 사이클 발생 여부
for i in range(e):
a, b = map(int, input().split())
# 사이클이 발생한 경우 종료
if find_parent(parent, a) == find_parent(parent, b):
cycle = True
break
else:
union_parent(parent, a, b)
if cycle:
print("사이클이 발생했습니다.")
else:
print("사이클이 발생하지 않았습니다.")
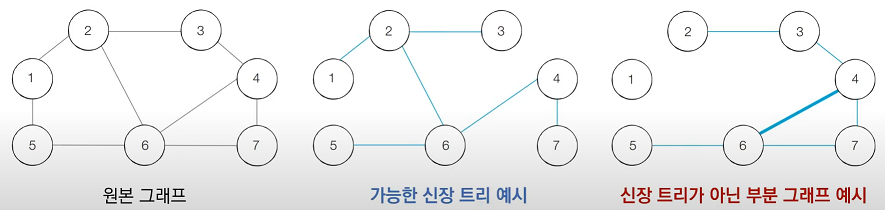
*신장 트리 : 하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프.
그래프 알고리즘 문제로 자주 출제되는 유형이다.
최소 신장 트리
최소 신장 트리에 포함된 간선의 개수는 (전체 노드의 개수-1) 이다. 기본적으로 트리가 가지는 특징이다.
# 특정 원소가 속한 집합을 찾기
def find_parent(parent, x):
# 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
# 두 원소가 속한 집합을 합치기
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
# 노드의 개수와 간선(union 연산)의 개수 입력받기
v, e = map(int, input().split())
parent = [0] * (v + 1) # 부모 테이블 초기화
# 모든 간선을 담을 리스트와, 최종 비용을 담을 변수
edges = []
result = 0
# 부모 테이블상에서, 부모를 자기 자신으로 초기화
for i in range(1, v + 1):
parent[i] = i
# 모든 간선에 대한 정보를 입력 받기
for _ in range(e):
a, b, cost = map(int, input().split())
# 비용순으로 정렬하기 위해서 튜플의 첫 번째 원소를 비용으로 설정
edges.append((cost, a, b))
# 간선을 비용순으로 정렬
edges.sort()
for edge in edges:
cost, a, b = edge
# 사이클이 발생하지 않는 경우에만 집합에 포함
if find_parent(parent, a) != find_parent(parent, b):
union_parent(parent, a, b)
result += cost
print(result)
간선의 개수가 E개일 때, O(ElogE)의 시간 복잡도를 가진다. (표준 정렬 라이브러리 기준)
*위상 정렬 : 사이클이 없는 방향 그래프의 모든 노드를 방향성에 거스르지 않도록 순서대로 나열하는 것
큐 또는 스택으로 구현할 수 있다.
1. 진입차수가 0인 노드를 큐에 넣는다.
2. 큐가 빌 때까지 다음의 과정을 반복한다.
큐에서 원소를 꺼내 해당 노드에서 출발하는 간선을 그래프에서 제거한다.
새롭게 진입차수가 0이 된 노드를 큐에 넣는다.
진입차수 : 특정한 노드로 들어오는 간선의 개수
진출차수 : 특정한 노드에서 나가는 간선의 개수
위상 정렬은 DAG(Direct Acyclic Graph: 순환하지 않는 방향 그래프)에 대해서만 수행할 수 있다.
# 큐를 이용한 위상 정렬
from collections import deque
# 노드의 개수와 간선의 개수 입력받기
v, e = map(int, input().split())
# 모든 노드에 대한 진입차수는 0으로 초기화
indegree = [0] * (v + 1)
# 각 노드에 연결된 간선 정보를 담기 위한 연결 리스트 초기화
graph = [[] for i in range(v +1)]
# 방향 그래프의 모든 간선 정보를 입력 받기
for _ in range(e):
a, b = map(int, input().split())
graph[a].append(b)
# 진입 차수를 1 증가
indegree[b] += 1
# 위상 정렬 함수
def topology_sort():
result = [] # 알고리즘 수행 결과를 담을 리스트
q = deque() # 큐 기능을 위한 deque 라이브러리 사용
# 처음 시작할 때는 진입차수가 0인 노드를 큐에 삽입
for i in range(1, v + 1 ):
if indegree[i] == 0:
q.append(i)
# 큐가 빌 때까지 반복
while q:
# 큐에서 원소 꺼내기
now = q.popleft()
result.append(now)
# 해당 원소와 연결된 노드들의 진입차수에서 1 빼기
for i in graph[now]:
indegree[i] -= 1
# 새롭게 진입차수가 0이 되는 노드를 큐에 삽입
if indegree[i] == 0:
q.append(i)
# 위상 정렬을 수행한 결과 출력
for i in result:
print(i, end=' ')
topology_sort()
모든 노드를 확인하며 각 노드에서 나가는 간선을 차례대로 제거해야하기 때문에 시간 복잡도는 O(V+E)이다.
data = input()
result = int(data[0])
for i in range(1, len(data)):
num = int(data[i])
if result <= 1 or num <= 1:
result += num
else:
result *= num
print(result)
n = int(input())
data = list(map(int, input().split()))
data.sort()
result = 0
f = 0.0
# 인원수가 가장 낮은 공포도보다 적으면 안됨
while len(data) > data[0]:
f += 1.0/float(data[0]) # 1/공포도 만큼을 인원수만큼 더해서 1이 넘으면 그룹 결성
data.pop(0) # 인원을 빼줌
if f >= 1.0:
result += 1
f = 0.0
print(result)
dx = [0, 0, -1, 1]
dy = [-1, 1, 0, 0]
move_types = ['L', 'R', 'U', 'D']
x, y = 1, 1
n = int(input())
plans = list(map(str, input().split()))
for plan in plans:
for i in range(len(move_types)):
if plan == move_types[i]:
nx = x + dx[i] # 반복문 안에서 선언된 변수도 외부에서 사용할 수 있는듯 하다
ny = y + dy[i] # c/c++이랑 다른 문법인것 같음
if nx < 1 or ny < 1 or nx > n or ny > n:
continue
x, y = nx, ny
print(x, y)
- 시각
범위가 하루로 잡혀있고 하루는 86400초이기 때문에 복잡하게 생각할 것 없이 단순하게 모든 초를 조사하면 된다
n = int(input())
three = 15 # 0~60 사이 3이 포함된 숫자의 개수
result = 0
for i in range(n+1):
if i==3 or i==13 or i==23: # 시간에 3이 포함되면 1시간 전체가 포함됨
result += 3600
else: # 분에 3이 포함되면 60초가 모두 포함되어야 하고 그 외엔 초에 포함된 3의 경우만 고려하면 됨
result += three * 60 + (60-three) * three
print(result)
평소처럼 단순하게 생각했으면 더 쉽게 풀수 있었을텐데 경우의 수를 계산하느라 시간제한 15분이 넘어버렸다
s = list(input())
s.sort() # 리스트로 입력 받고 정렬
result = 0
while True:
# 오름차순 정렬 시 맨 앞에는 숫자가 오므로 숫자인지 판별
if s[0].isdigit():
result += int(s[0])
# 다음 문자 확인을 위해 리스트에서 제거
s.remove(s[0])
else:
break
print(''.join(s)+str(result))
이코테에서는 입력받은 문자열을 모두 순회하면서 문자는 리스트에, 숫자는 합산해서 따로 관리 후 마지막에 숫자 합을 리스트에 추가시켜서 출력함
다만 이런경우는 문자열 관련 기능이 강력한 파이썬에서나 가능한거고 c/c++ 환경에서는 완전 탐색으로 구현해야 할 것 같다
- 게임 개발
문제 이해하는게 가장 어려움. dx, dy라는 별도의 벡터를 이용하여 구현하면 어렵지 않음
# # 0:북 1:동 2:남 3:서
# # 0:육지 1:바다
n, m = map(int, input().split())
x, y, direction = map(int, input().split())
# 이동 벡터
dx = [0, 1, 0, -1]
dy = [-1, 0, 1, 0]
d = [[0] * m for _ in range(n)]
d[x][y] = 1 # 첫 위치는 방문한걸로 기록
map_list = []
for i in range(n):
map_list.append(list(map(int, input().split())))
def turn_left():
global direction
direction -= 1
if direction < 0:
direction = 3
turn_time = 0
count = 1
while True:
turn_left()
nx = x + dx[direction]
ny = y + dy[direction]
# 방문한적이 있거나 바다인 경우
if d[nx][ny] == 1 or map_list[nx][ny] == 1:
turn_time += 1
else:
d[nx][ny] = 1
x = nx
y = ny
count += 1
turn_time = 0
continue
# 4번의 회전을 모두 한 경우
if turn_time == 4:
nx = x - dx[direction]
ny = y - dy[direction]
# 뒤가 바다라면 시뮬레이션 종료
if map_list[nx][ny] == 1:
break
else:
x = nx
y = ny
turn_time = 0
print(count)
[DFS/BFS]
- 음료수 얼려 먹기
주어진 노드들을 따로 관리할 필요가 없으므로 visited를 별도로 관리하지 않아도 되고 DFS로 구현하면 된다
# N x M 얼음틀
# 구멍이 뚫린 부분은 0, 칸막이가 존재하는 부분은 1
# 구멍이 뚫린 부분끼리 상, 하, 좌, 우가 붙어있는 경우 서로 붙은것으로 간주
n, m = map(int, input().split())
graph = []
for i in range(n):
graph.append(list(map(int, input())))
def dfs(x, y):
# 범위를 벗어나는 경우 즉시 종료
if x <= -1 or x >= n or y <= -1 or y >= m:
return False
# 아직 방문하지 않은 곳일 때
if graph[x][y] == 0:
# 방문처리 후 상하좌우 모두 탐색
graph[x][y] = 1
dfs(x+1, y)
dfs(x-1, y)
dfs(x, y+1)
dfs(x, y-1)
return True
return False
count = 0
# 모든 노드에 대하여 조사
for i in range(n):
for j in range(m):
if dfs(i, j) == True:
count += 1
print(count)
- 미로 탈출
노드간의 간선 값이 모두 1이므로 목표지점까지의 최단거리를 보장할 수 있다. BFS로 구현
# 미로의 크기는 NxM이고 출구는 좌표는 (N, M)
from collections import deque
n, m = map(int, input().split())
# 상, 하, 좌, 우
dx = (-1, 1, 0, 0)
dy = (0, 0, -1, 1)
maze = []
for i in range(n):
maze.append(list(map(int, input())))
def bfs(x, y):
queue = deque()
# 최초 시작노드 큐에 삽입
queue.append((x, y))
while queue:
x, y = queue.popleft()
# 각 노드에 연결된 최대 4방향에 대해 확인
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if nx <= -1 or nx >= n or ny <= -1 or ny >= m:
continue
if maze[nx][ny] == 0:
continue
if maze[nx][ny] == 1:
maze[nx][ny] = maze[x][y] + 1
queue.append((nx, ny))
return maze[n-1][m-1]
print(bfs(0, 0))
# 두 배열을 각각 오름차순, 내림차순 정렬 후 k만큼 앞에서 부터 바꿔주면 됨
n, k = map(int, input().split())
aArr = list(map(int, input().split()))
bArr = list(map(int, input().split()))
aArr.sort() # 오름차순
bArr.sort(reverse=True) # 내림차순
for i in range(k):
if aArr[i] < bArr[i]: # a보다 b가 큰 경우 서로 값을 바꿔줌
aArr[i], bArr[i] = bArr[i], aArr[i]
# 더이상 a보다 큰 수는 없으면 루프 탈출
else:
break
print(sum(aArr))
n, m = map(int, input().split())
hlist = list(map(int, input().split()))
start = 0
end = max(hlist)
result = 0
while start <= end:
total = 0
mid = (start + end) // 2
for x in hlist:
# 잘랐을 때 떡의 양 계산
if x > mid:
total += x - mid
# 떡의 양이 작으면 자르는 높이를 줄인다
if total < m:
end = mid - 1
# 떡의 양이 많으면 자르는 높이를 늘린다
# 최대한 덜 자르는게 목표이므로 이때 결과값을 보관해둔다
else:
start = mid + 1
result = mid
print(result)
이 문제의 경우 이진 탐색을 이용한다고 해서 데이터의 정렬이 반드시 필요한 것은 아니다
찾아야 하는 해가 계속 바뀌기 때문에 탐색 과정에 이진 탐색의 개념만 도입하여 파라메트릭 서치로 바꾼것이다
- 정렬된 배열에서 특정 수의 개수 구하기
bisect(C++에서는 lower_bound, upper_bound) 사용시 매우 쉽게 구할 수 있다
def bisect_left(array, x):
start = 0
end = len(array) - 1
result = 0
while start <= end:
mid = (start + end) // 2
# 값을 찾았다면 루프 종료가 아니라 mid 값을 보관하고 중복된 값을 찾으러 범위를 좁혀준다
# 왼쪽을 찾아야 하므로 끝점을 땡겨준다
if array[mid] == x:
result = mid
end = mid - 1
elif array[mid] > x:
end = mid - 1
else:
start = mid + 1
# 값 삽입시 현재 인덱스의 위치에 삽입하고 밀어내면 된다
return result
def bisect_right(array, x):
start = 0
end = len(array) - 1
# 마지막에 1을 더해주기 때문에 0을 만들어주기 위해 -1 대입
result = -1
while start <= end:
mid = (start + end) // 2
# 값을 찾았다면 루프 종료가 아니라 mid 값을 보관하고 중복된 값을 찾으러 범위를 좁혀준다
# 오른쪽을 찾아야 하므로 시작점을 끌어올려준다
if array[mid] == x:
result = mid
start = mid + 1
elif array[mid] > x:
end = mid - 1
else:
start = mid + 1
# 값 삽입시 현재 인덱스보다 오른쪽에 삽입해야 하기때문에 1을 더해준다
return result + 1
n, x = map(int, input().split())
array = list(map(int, input().split()))
result = bisect_right(array, x) - bisect_left(array, x)
if result == 0:
print(-1)
else:
print(result)
아래처럼 bisect 라이브러리를 이용해서 쉽고 간단하게 구현할 수 있지만 연습을 위해 직접 구현
실제 bisect는 값을 찾지 못하면 정렬이 깨지지 않는 적절한 인덱스를 반환한다
그것에 맞춰서 수정한건 아래와 같다
def bisect_left(array, x):
start = 0
end = len(array) - 1
# 찾는 값이 리스트 안의 모든 값보다 클때 result값이 변하는 일이 없으므로 미리 삽입될 끝 인덱스 지정
result = len(array)
while start <= end:
mid = (start + end) // 2
# 값을 찾았다면 루프 종료가 아니라 mid 값을 보관하고 중복된 값을 찾으러 범위를 좁혀준다
# 왼쪽을 찾아야 하므로 끝점을 땡겨준다
# 값을 찾지 못한경우 적절한 위치를 찾기 위해 부등호 >= 를 사용해준다
if array[mid] >= x:
result = mid
end = mid - 1
elif array[mid] > x:
end = mid - 1
else:
start = mid + 1
# 값 삽입시 현재 인덱스의 위치에 삽입하고 밀어내면 된다
return result
def bisect_right(array, x):
start = 0
end = len(array) - 1
# 마지막에 1을 더해주기 때문에 0을 만들어주기 위해 -1 대입
result = -1
while start <= end:
mid = (start + end) // 2
# 값을 찾았다면 루프 종료가 아니라 mid 값을 보관하고 중복된 값을 찾으러 범위를 좁혀준다
# 오른쪽을 찾아야 하므로 시작점을 끌어올려준다
# 값을 찾지 못한경우 적절한 위치를 찾기 위해 부등호 <= 를 사용해준다
if array[mid] <= x:
result = mid
start = mid + 1
elif array[mid] > x:
end = mid - 1
else:
start = mid + 1
# 값 삽입시 현재 인덱스보다 오른쪽에 삽입해야 하기때문에 1을 더해준다
return result + 1
값을 찾지 못한경우 두 함수의 반환값은 모두 같다. 실제 bisect_left, bisect_right와 동일한 반환값을 가진다
따로 구현하지 않고 사용시에는 최상단에 from bisect import bisect_left, bisect_right 를 선언해주고 동일하게 쓰면 된다
x = int(input())
dp = [0] * 30001
# Bottom-up
# dp[1]은 0이라서 2부터 수행이 가능하다
for i in range(2, x + 1):
# 현재 수에서 1을 빼는경우. 연산횟수 1회가 증가된다
dp[i] = dp[i - 1] + 1
if i % 2 == 0:
# 현재 수가 2로 나누어 떨어지는 경우, 1을 뺀 현재 연산횟수보다
# 2로 나누었을때의 연산횟수가 더 적은지 확인한다.
# 2로 나누는 과정 자체도 한번의 연산횟수이기 때문에 1을 더해준 값을 비교한다.
# 좌항은 연산횟수 1을 안더하는 이유는 이미 위에서 더해줬기 때문이다.
dp[i] = min(dp[i], dp[i // 2] + 1)
# 3으로 나누어 떨어지는 경우
if i % 3 == 0:
dp[i] = min(dp[i], dp[i // 3] + 1)
# 5로 나누어 떨어지는 경우
if i % 5 == 0:
dp[i] = min(dp[i], dp[i // 5] + 1)
# dp에 저장된 값만 꺼내오면 된다
print(dp[x])
그리디처럼 큰 수인 5로 먼저 나누는것이 항상 능사가 아닌것을 알아야한다.
예를들어 27인경우 5로 먼저 나누려고 하면 26-25-5-1 총 4번의 연산이 이루어지지만 3으로 나눈다면 9-3-1 총 3번의 연산만으로 1을 만들수 있다. 그렇기에 그리디로는 풀 수 없다.
n, m = map(int, input().split())
dp = [10001] * (m + 1)
money = []
for i in range(n):
money.append(int(input()))
dp[0] = 0
for i in money:
for j in range(i, m + 1):
# (i-k)원을 만드는 방법이 존재하는 경우
if dp[j - i] != 10001:
# 1을 더해주는 이유는 화폐 장수 한장이 추가되기 때문
dp[j] = min(dp[j], dp[j - i] + 1)
if dp[m] == 10001:
print(-1)
else:
print(dp[m])
문제를 잘못 이해해서 30분정도 삽질을 했었다. 심플하게 잘 풀었다고 생각했는데 조건 자체가 잘못됐었음
from sys import stdin
input = stdin.readline
# 무한 값
INF = int(1e9)
n, m = map(int, input().split())
# 최단 거리 테이블 값을 무한으로 초기화
table = [[INF] * (n + 1) for _ in range(n + 1)]
# 자기 자신에서 자기 자신으로 가는 거리는 0
for i in range(1, n+1):
table[i][i] = 0
for i in range(m):
x1, x2 = map(int, input().split())
# 양방향이면서 거리가 모두 1
table[x1][x2] = 1
table[x2][x1] = 1
# 목적지 x와 경유지k
x, k = map(int, input().split())
# 정점 개수만큼 순회 O(N)
for i in range(1, n + 1):
# 2차원 최단 거리 테이블 갱신 O(N²)
for x1 in range(1, n + 1):
for x2 in range(1, n + 1):
table[x1][x2] = min(table[x1][x2], table[x1][i] + table[i][x2])
# 1부터 경유지까지의 거리 + 경유지부터 목적지까지의 거리
distance = table[1][k] + table[k][x]
# INF가 넘는다면 경로가 없음
if distance >= INF:
print(-1)
else:
print (distance)
from sys import stdin
import heapq
input = stdin.readline
# 무한 값
INF = int(1e9)
n, m, c = map(int, input().split())
graph = [[] for _ in range(n + 1)]
distance = [INF] * (n + 1)
for _ in range(m):
x, y, z = map(int, input().split())
graph[x].append((y, z))
def dijkstra(start):
q = []
heapq.heappush(q, (0, start))
distance[start] = 0
while q:
dist, now = heapq.heappop(q)
if dist > distance[now]:
continue
for x in graph[now]:
cost = dist + x[1]
if cost < distance[x[0]]:
distance[x[0]] = cost
heapq.heappush(q, (cost, x[0]))
dijkstra(c)
count = 0
max_distance = 0
# 도달할 수 있는 노드중 가장 멀리있는 노드와의 최단거리
for x in distance:
if x != INF:
count += 1
max_distance = max(max_distance, x)
# 시작 노드는 제외해야 하므로 -1
print(count - 1, max_distance)
from sys import stdin
input = stdin.readline
# 부모 리스트, 찾을값
def find_parent(parent, x):
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
n, m = map(int, input().split())
parent = [x for x in range(n + 1)] # 부모 리스트 초기화
for i in range(m):
x, a, b = map(int, input().split())
# union
if x == 0:
union_parent(parent, a, b)
# find
else:
if find_parent(parent, a) == find_parent(parent, b): # 서로의 루트가 같다면
print("YES")
else:
print("NO")
from sys import stdin
input = stdin.readline
def find_parent(parent, x):
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
# 노드n 간선m. a,b,c : a-b의 연결비용 c
n, m = map(int, input().split())
parent = [x for x in range(n + 1)]
edges = [] # 간선 저장 리스트
for i in range(m):
a, b, c = map(int, input().split())
edges.append((c, a, b))
edges.sort()
answer = 0
max_cost = 0
for edge in edges:
cost, a, b = edge
# 사이클이 아닌 경우만 수행
if find_parent(parent, a) != find_parent(parent, b):
union_parent(parent, a, b)
answer += cost
max_cost = cost # 비용순으로 정렬되어서 가장 마지막에 들어온 값이 클수밖에 없음
# 가장 높은 비용을 빼서 트리를 2개로 분리
print(answer - max_cost)