항목 34 : 정렬된 범위에 대해 동작하는 알고리즘이 어떤 것들인지 파악해 두자
반드시 정렬된 컨테이너에만 사용할 수 있는 알고리즘들이 존재한다.
대체로 이진 탐색이나 순차접근으로 동작하는 알고리즘들이 그렇다.
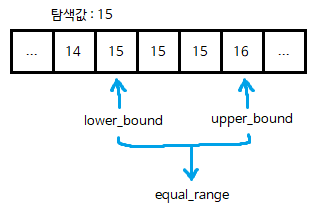
binary_search, lower_bound, upper_bound, equal_range
set_union, set_itersection, set_difference, set_symmetric_difference
merge, inplace_merge
includes
unique, unique_copy는 정렬된 범위에 사용하는 편이지만 꼭 그렇지 않아도 된다.
또한 알고리즘들은 대체로 오름차순을 가정하고 동작하기 때문에 내림차순이 필요하면 알맞는 비교 함수를 넘겨주어야 한다.
그리고 unique, unique_copy를 제외한 정렬된 범위에 동작하는 모든 알고리즘은 두 값이 같은지를 판단할 때 동등성을 기준으로 삼는다. unique, unique_copy는 상등성이다.
항목 35 : 대소문자를 구분하지 않는 문자열 비교는 mismatch 아니면 lexicographical_compare를 써서 간단히 구현할 수 있다
◾ mismatch (최초로 달라지는 지점)
int ciCharCompare(char c1, char c2) // 문자를 소문자로 변환해서 비교. strcmp 형식
{
int lc1 = tolower(static_cast<unsigned char>(c1));
int lc2 = tolower(static_cast<unsigned char>(c2));
if (lc1 < lc2) return -1;
if (lc1 > lc2) return 1;
return 0;
}
대소문자를 구별하지 않고 비교하는 쉬운 방법은 문자열을 문자단위로 모두 소문자나 대문자로 바꾸고 하나씩 비교하면 된다.
int ciStringCompareImpl(const std::string& s1, const std::string& s2) // mismatch
{
typedef std::pair<std::string::const_iterator, std::string::const_iterator> PSCI;
PSCI p = std::mismatch(s1.begin(), s1.end(), s2.begin(),
std::not2(std::ptr_fun(ciCharCompare)));
if (p.first == s1.end()) {
if (p.second == s2.end()) return 0;
else return -1;
return ciCharCompare(*p.first, *p.second);
}
}
int ciStringCompare(const std::string& s1, const std::string& s2) // 문자열 길이 판별
{
if (s1.size() <= s2.size()) return ciStringCompareImpl(s1, s2);
else return -ciStringCompareImpl(s2, s1);
}
위의 비교함수를 토대로 문자열로 확장시켜서 사용한다.
mismatch는 두 문자열중 하나가 다른것보다 길이가 짧을 때, 짧은 문자열 쪽을 첫째 매개변수로 넘겨주어야 한다.
반환값으로 두 범위 안의 문자가 처음으로 맞지 않기 시작하는 위치를 pair로 반환해준다.
...
std::not2(std::ptr_fun(ciCharCompare)));
// std::not2 -> 이항 조건자 함수의 결과를 뒤집는 함수 객체 생성
// std::ptr_fun -> 함수 래퍼 객체 생성. 함수를 함수 객체로 만들어준다. std::function과 비슷한 듯
mismatch의 마지막 인자로 넘어가는 함수가 특이하게 생겼는데, mismatch는 넘겨준 함수가 false를 반환하면 즉시 중단한다. 근데 만들어둔 함수는 문자가 같으면 0을 반환하기 때문에 암시적으로 false로 변환되므로 결과를 반대로 해줄 필요가 있다.
◾ lexicographical_compare (
bool ciCharLess(char c1, char c2)
{
return tolower(static_cast<unsigned char>(c1)) < tolower(static_cast<unsigned char>(c2));
}
bool ciStringCompare(const std::string& s1, const std::string& s2)
{
return std::lexicographical_compare(s1.begin(), s1.end(), s2.begin(), s2.end(), ciCharLess);
}
mismatch보다 훨씬 간결하다. 마치 strcmp를 일반화한 알고리즘이다.
두 요소를 비교해서 true가 반환되면 서로 다른값으로 판단하고 본인 역시 true를 반환한다.
◾ mismatch
문자열 길이가 짧은것을 첫 번째 인자로 넘겨주어야 한다.
인자로 넘겨준 비교 함수가 true를 반환하면 최초로 값이 다른 지점의 반복자를 pair로 반환해준다.
◾ lexicographical_compare
인자로 넘겨준 비교 함수가 최초로 값이 다른 지점을 찾으면 true를 반환하고 스스로도 true를 반환한다.
결과적으로 mismatch와 lexicographical_compare는 최초로 값이 다른 부분을 만나면 실행이 중단되는 것이다.
만약 오직 문자열 비교만을 할거라면 stricmp를 사용하는게 성능상 더 좋긴 하다. (속도가 중요한 PS에 유용할 것)
항목 36 : copy_if를 적절히 구현해 사용하자
(참고: copy_if도 이제는 표준 알고리즘이다.)
template<typename InputIterator, typename OutputIterator, typename Predicate>
OutputIterator copy_if(InputIterator begin, OutputIterator end,
OutputIterator destBegin, Predicate p)
{
while (begin != end) {
if (p(*begin)) *destBegin++ = *begin; // 아마도 destBegin은 공간을 미리 확보해야 할 것이다
++begin;
}
return destBegin;
}
항목 37 : 범위 내의 데이터 값을 요약하거나 더하는 데에는 accumulate나 for_each를 사용하자
◾ accumulate (범위 내 원소들의 총합, 누적합)
algorithm 헤더가 아닌 numeric 헤더에 들어있다. 추가로 inner_product(내적), adjacent_difference(인접 원소의 차), partial_sum(부분합)이 있다.
초기 값을 받아들이는 알고리즘 사용에 대해 주의할점이 있다. 받아들인 값의 타입 그대로 반환되기 때문에 int로 넘겨주고 double로 반환받길 기대한다던지, 혹은 long long같은 큰 수를 반환받길 기대하는것은 계산 오류나 오버플로우가 발생할 수 있다.
/* accumulate */
std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::accumulate(v.begin(), v.end(), 0);
// 55
/* inner_product */
std::vector<int> v1 = {2, 3, 4};
std::vector<int> v2 = {5, 6, 7};
std::inner_product(v1.begin(), v1.end(), v2.begin(), 0);
// 2*5 + 3*6 + 4*7 = 56
/* adjacent_difference */
std::vector<int> v1 = {1, 2, 5, 10, 15, 12, 20};
std::vector<int> v2;
std::adjacent_difference(v1.begin(), v1.end(), std::back_inserter(v2));
// v2: 1 1 3 5 5 -3 8
/* partial_sum */
std::vector<int> v1 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::vector<int> v2;
std::partial_sum(v1.begin(), v1.end(), std::back_inserter(v2));
// v2: 1 3 6 10 15 21 28 36 45 55
만약 계산하는데 직접 만든 함수를 사용한다면 계산 결과를 타입에 맞게 반환해주어야 한다.
기본적으로 사칙연산에 대한 표준 함수자 클래스가 만들어져있다.
여담으로 C++ 표준안에 의하면 accumulate에 넘겨지는 함수의 side effect는 없어야 한다고 한다.
◾ for_each
범위 내의 요소에 대해 함수 객체를 호출한다. 여기서는 side effect를 가져도 된다.
accumulate와 다르게 매개 변수로 받은 함수 객체를 반환한다.
만약 실행 결과값이 필요하다면 함수 객체에서 요약 정보를 뽑아낼 방법을 정의해두어야 한다.
accumulate는 함수 객체의 반환값이 존재해야 하고 연산 결과를 값으로 반환하지만, for_each는 함수 객체의 반환값이 없고 연산 결과가 필요하다면 별도의 함수를 정의해야한다.